// open source · BETA
AI shouldn't have a meter.
Unlimited tokens. Forever.
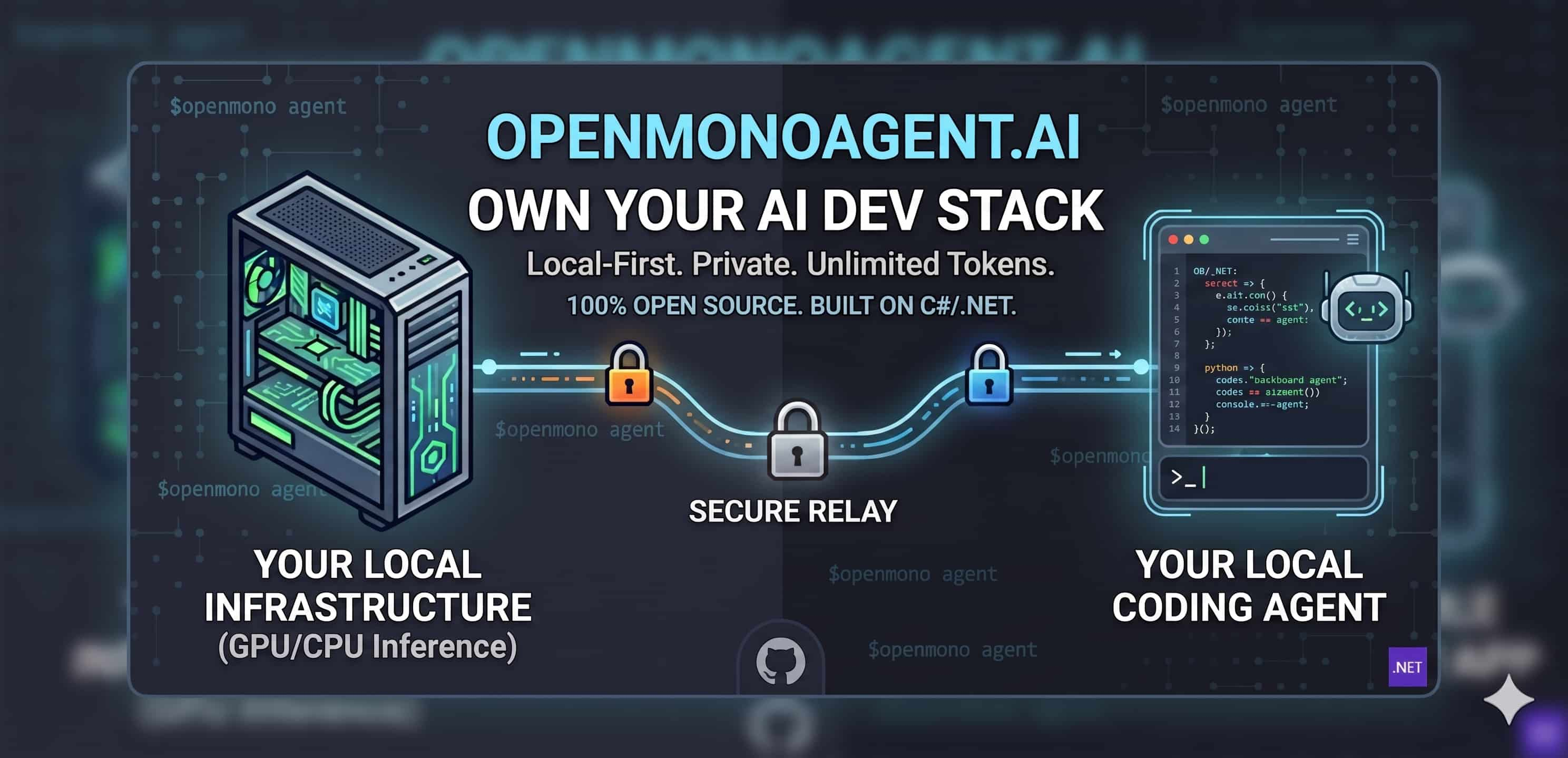
Your machine. Your agent. Use it from anywhere. OpenMonoAgent.ai is a terminal-native coding agent powered by local LLMs — 100% open source, free forever, and installed with a single command. Proudly built on C#/.NET, because AI tooling should be infrastructure, not a subscription.
A PROJECT BY 
$bash <(curl -fsSL
https://raw.githubusercontent.com/StartupHakk/OpenMonoAgent.ai/refs/heads/main/get-openmono.sh) ✓ installed. # No API keys. No cloud. Just your machine. $openmono agent → Detected Docker, NVIDIA runtime → Starting llama-server :7474 ✓ Ready. 20 tools + MCP registered. Context: 196k. you ›refactor Program.cs to use async/await → reading Program.cs (142 lines) → analyzing with Roslyn (blast-radius: 3 call sites) → proposing edit… [approve? y/N] ✓ Patched. 0 bytes left your machine.